子 Agent 与上下文隔离 — 让 Agent 学会委派
在 GitHub 编辑此页上一章我们学习了任务规划。但有些子任务非常复杂,需要大量工具调用和中间处理——如果全在主 Agent 里完成,上下文很快就会爆炸。本章学习 Deep Agents 的另一个核心能力:子 Agent(Subagent),让主 Agent 学会”委派”。
为什么需要子 Agent?
上下文膨胀问题
假设主 Agent 要完成一个研究报告,其中一个子任务是”搜索 LangGraph 的技术文档”。这个子任务可能涉及:
- 5 次网络搜索调用
- 每次返回 3000+ tokens 的搜索结果
- 多次
write_file保存中间结果 - 多次
read_file回顾和整理
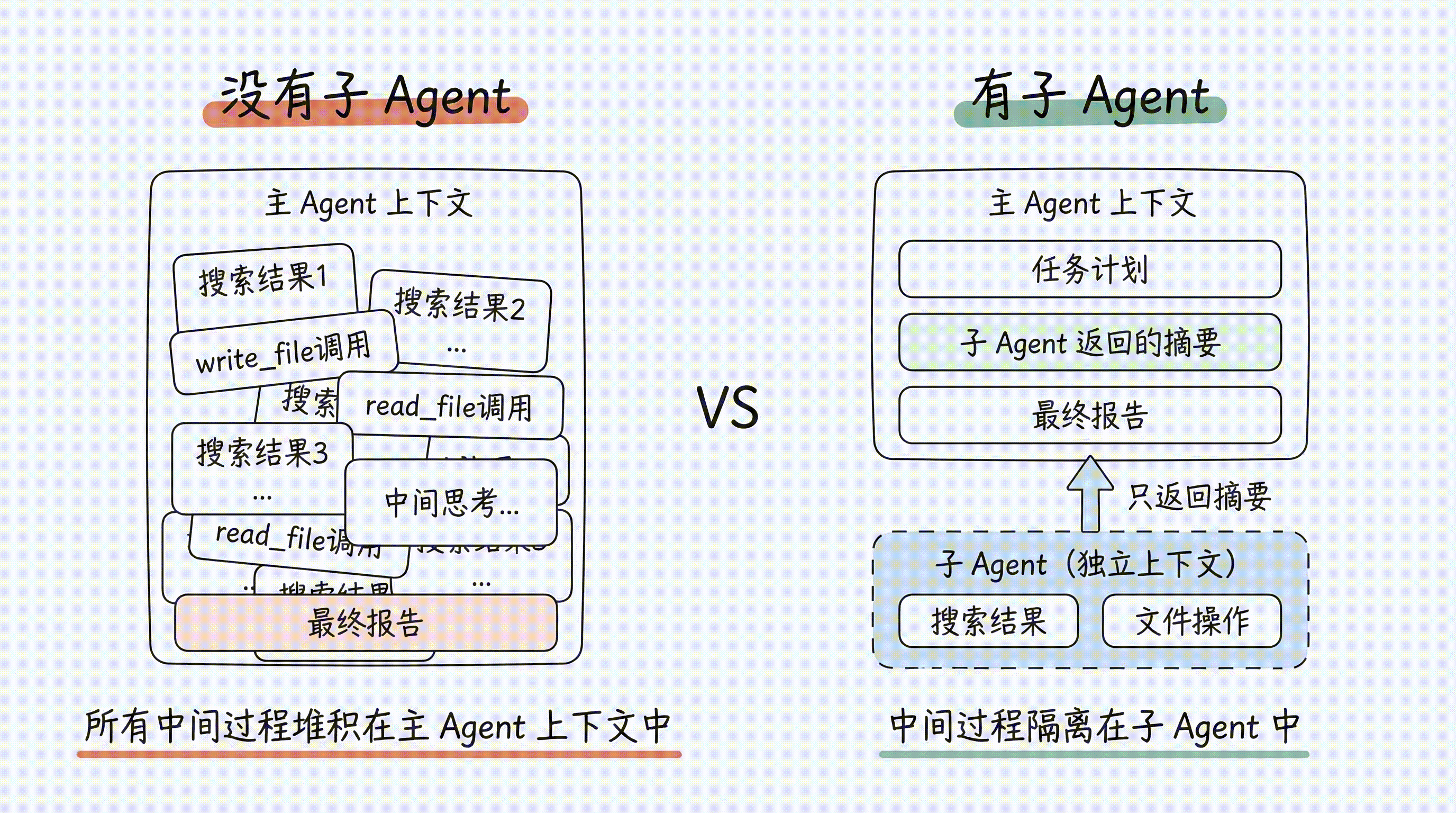
这些中间过程产生了大量的工具调用记录,全部堆在主 Agent 的上下文里。虽然第 3 章的自动卸载机制能缓解一部分,但主 Agent 其实根本不需要知道这些细节——它只需要最终的研究摘要。
Context Quarantine(上下文隔离)
这就是子 Agent 的核心设计动机:Context Quarantine(上下文隔离)。
工作方式很简单:
- 主 Agent 通过
task工具创建一个子 Agent - 子 Agent 在独立的上下文中执行任务(自己的工具调用、文件操作都不会回到主 Agent)
- 子 Agent 完成后,只把最终结果返回给主 Agent
- 主 Agent 的上下文保持干净
打个比方:主 Agent 是项目经理,子 Agent 是专项负责人。项目经理不需要参加每一个技术讨论会——他只需要看到每个负责人提交的总结报告。
什么时候用子 Agent?
| 场景 | 是否用子 Agent | 理由 |
|---|---|---|
| 需要多次搜索和整理的研究任务 | ✅ | 大量中间结果会膨胀主 Agent 上下文 |
| 需要特殊工具或指令的专业任务 | ✅ | 子 Agent 可以有自己的工具集和系统提示词 |
| 需要不同模型能力的任务 | ✅ | 子 Agent 可以用不同的模型 |
| 需要高层协调的复杂任务 | ✅ | 主 Agent 专注协调,子 Agent 专注执行 |
| 单步简单查询 | ❌ | 委派开销大于收益 |
| 需要保留中间上下文的任务 | ❌ | 子 Agent 的上下文不回传给主 Agent |
定义子 Agent:字典方式
最常用的方式是用字典定义子 Agent:
from deepagents import create_deep_agent
# 定义一个研究型子 Agent
research_subagent = {
"name": "researcher", # 必填:唯一标识符
"description": "深入研究特定主题,搜索多个信息源并整理成摘要", # 必填:主 Agent 靠它决定何时委派
"system_prompt": """你是一位专业的研究员。你的任务是:
1. 把研究问题拆解为多个搜索查询
2. 用 internet_search 搜索相关信息
3. 整理发现,写成简洁摘要
4. 列出关键发现和信息来源
注意:返回结果控制在 500 字以内,只返回核心发现。""", # 必填:子 Agent 自己的指令
"tools": [internet_search], # 可选,默认继承;显式指定后完全替换(不合并)
"skills": ["/skills/research/"], # 可选,不继承主 Agent;指定后独立运行 SkillsMiddleware
}
agent = create_deep_agent(
model="google_genai:gemini-3.1-pro-preview",
skills=["/skills/main/"], # 主 Agent 和 general-purpose 子 Agent 继承此处
subagents=[research_subagent], # researcher 只获得 /skills/research/,不获得 /skills/main/
)字段说明
| 字段 | 必填 | 继承主 Agent? | 说明 |
|---|---|---|---|
name | ✅ | — | 唯一标识符,主 Agent 通过它指定委派给谁;同时作为流式输出和追踪中的 lc_agent_name 元数据 |
description | ✅ | — | 描述子 Agent 的能力,主 Agent 靠它决策路由 |
system_prompt | ✅ | ❌ 不继承 | 子 Agent 自己的指令,需要独立定义 |
tools | 可选 | ✅ 默认继承,指定后完全替换 | 子 Agent 工具集;不指定则继承主 Agent 的所有工具,指定后完全替换(不合并) |
model | 可选 | ✅ 默认继承 | 可指定不同模型,支持 LangChain 对象或 "provider:model" 字符串(如 "openai:gpt-5.4") |
middleware | 可选 | ❌ 不继承 | 子 Agent 自己的中间件 |
interrupt_on | 可选 | ✅ 默认继承 | 子 Agent 的人工审批配置,可覆盖主 Agent |
skills | 可选 | ❌ 不继承 | 子 Agent 自己的 Skills 路径;指定后子 Agent 运行独立的 SkillsMiddleware,技能状态与主 Agent 完全隔离 |
response_format | 可选 | ❌ 不继承 | 结构化输出 schema(需 deepagents>=0.5.3);设置后主 Agent 收到 JSON 而非自由文本 |
permissions | 可选 | ✅ 默认继承,指定后完全替换 | 文件系统权限规则;指定后完全替换主 Agent 的权限配置 |
关键点:子 Agent 的 system_prompt 不继承主 Agent——每个子 Agent 应有自己专属的指令。tools 默认继承主 Agent 的工具集,但一旦显式指定就会完全替换(不是合并)。skills 也不继承——主 Agent 的 skills 只会传给 general-purpose 子 Agent,其他子 Agent 需要显式配置自己的 skills 路径。
General-purpose 子 Agent:默认的”万能助手”
即使你不定义任何子 Agent,Deep Agents 也自带一个 general-purpose 子 Agent。它是唯一的例外——继承主 Agent 的 system_prompt、tools、model 和 skills。
# 不传 subagents 参数,也能用子 Agent
agent = create_deep_agent(
model=model,
tools=[internet_search],
system_prompt="你是一位研究助手。",
)
# 主 Agent 可以这样委派:
# task(name="general-purpose", task="搜索量子计算的最新进展")General-purpose 子 Agent 的作用是纯粹的上下文隔离——它和主 Agent 有相同的能力,但在独立的上下文中工作。主 Agent 不需要承受子任务中 10 次搜索带来的上下文膨胀,只需要收到一份精炼的摘要。
禁用 general-purpose 子 Agent
如果你不想让 Agent 拥有 task 工具,可以完全禁用子 Agent 机制:
from deepagents import create_deep_agent
from deepagents.profiles import GeneralPurposeSubagentProfile, HarnessProfile
# 两步缺一不可
agent = create_deep_agent(
model=model,
subagents=[], # 不传任何同步子 Agent
profile=HarnessProfile(
general_purpose_subagent=GeneralPurposeSubagentProfile(enabled=False)
),
)⚠️ 不要用
excluded_middleware来排除SubAgentMiddleware——这会直接抛出ValueError。正确做法是通过GeneralPurposeSubagentProfile(enabled=False)关闭。
覆盖 general-purpose 子 Agent
如果你想给默认子 Agent 配置不同的模型或工具,可以用 name="general-purpose" 来覆盖:
agent = create_deep_agent(
model=model, # 主 Agent 用 GLM-4-9B
tools=[internet_search],
subagents=[
{
"name": "general-purpose", # 覆盖默认
"description": "通用助手,处理各种委派任务",
"system_prompt": "你是一个通用助手。",
"tools": [internet_search],
"model": ChatOpenAI( # 子 Agent 用更强的模型
model="Pro/zai-org/GLM-5",
api_key=os.environ["SILICONFLOW_API_KEY"],
base_url="https://api.siliconflow.cn/v1",
),
},
],
)CompiledSubAgent:集成 LangGraph 工作流
对于更复杂的场景,你可以用一个预构建的 LangGraph 图作为子 Agent。这适用于需要多步骤、有分支逻辑的工作流:
from deepagents import create_deep_agent, CompiledSubAgent
from langchain.agents import create_agent
# 用 LangChain 创建一个自定义 Agent 图
custom_graph = create_agent(
model=model,
tools=[statistical_analysis, generate_chart],
system_prompt="你是数据分析专家,擅长统计分析和可视化。",
)
# 包装为 CompiledSubAgent
data_subagent = CompiledSubAgent(
name="data-analyzer",
description="执行复杂的数据分析任务,包括统计分析和图表生成",
runnable=custom_graph, # 传入编译好的 LangGraph 图
)
agent = create_deep_agent(
model=model,
subagents=[data_subagent],
)CompiledSubAgent 的要求:传入的 LangGraph 图的 State 中必须包含 "messages" 键。
字典 vs CompiledSubAgent:怎么选?
| 场景 | 推荐方式 | 理由 |
|---|---|---|
| 大多数情况 | 字典方式 | 简单直观,配置灵活 |
| 子 Agent 需要复杂的多步骤工作流 | CompiledSubAgent | 可以用 LangGraph 的图 API 定义分支、循环 |
| 子 Agent 已经有现成的 LangGraph 图 | CompiledSubAgent | 直接复用,无需重写 |
多子 Agent 协作模式
实际项目中,最常见的模式是多个专业子 Agent 协作,由主 Agent 作为协调者:
import os
from langchain_openai import ChatOpenAI
from deepagents import create_deep_agent
model = ChatOpenAI(
model="THUDM/glm-4-9b-chat", # 免费模型,可替换为 "Pro/zai-org/GLM-5"
api_key=os.environ["SILICONFLOW_API_KEY"],
base_url="https://api.siliconflow.cn/v1",
)
subagents = [
{
"name": "data-collector",
"description": "从多个来源收集原始数据,包括网络搜索和 API 调用",
"system_prompt": "你是数据收集专家。搜索并整理相关数据,返回结构化的数据摘要。",
"tools": [internet_search, api_call],
},
{
"name": "data-analyzer",
"description": "对收集到的数据进行统计分析,提取关键洞察",
"system_prompt": "你是数据分析专家。分析数据并提取 3-5 个关键发现,控制在 300 字以内。",
"tools": [statistical_analysis],
},
{
"name": "report-writer",
"description": "根据分析结果撰写专业报告",
"system_prompt": "你是技术写作专家。根据提供的分析结果撰写清晰、专业的报告。",
"tools": [format_document],
},
]
agent = create_deep_agent(
model=model,
system_prompt="""你是一位项目协调者。面对复杂任务时:
1. 先用 write_todos 制定计划
2. 将数据收集委派给 data-collector
3. 将分析工作委派给 data-analyzer
4. 将报告撰写委派给 report-writer
5. 整合各子 Agent 的输出,形成最终结果""",
subagents=subagents,
)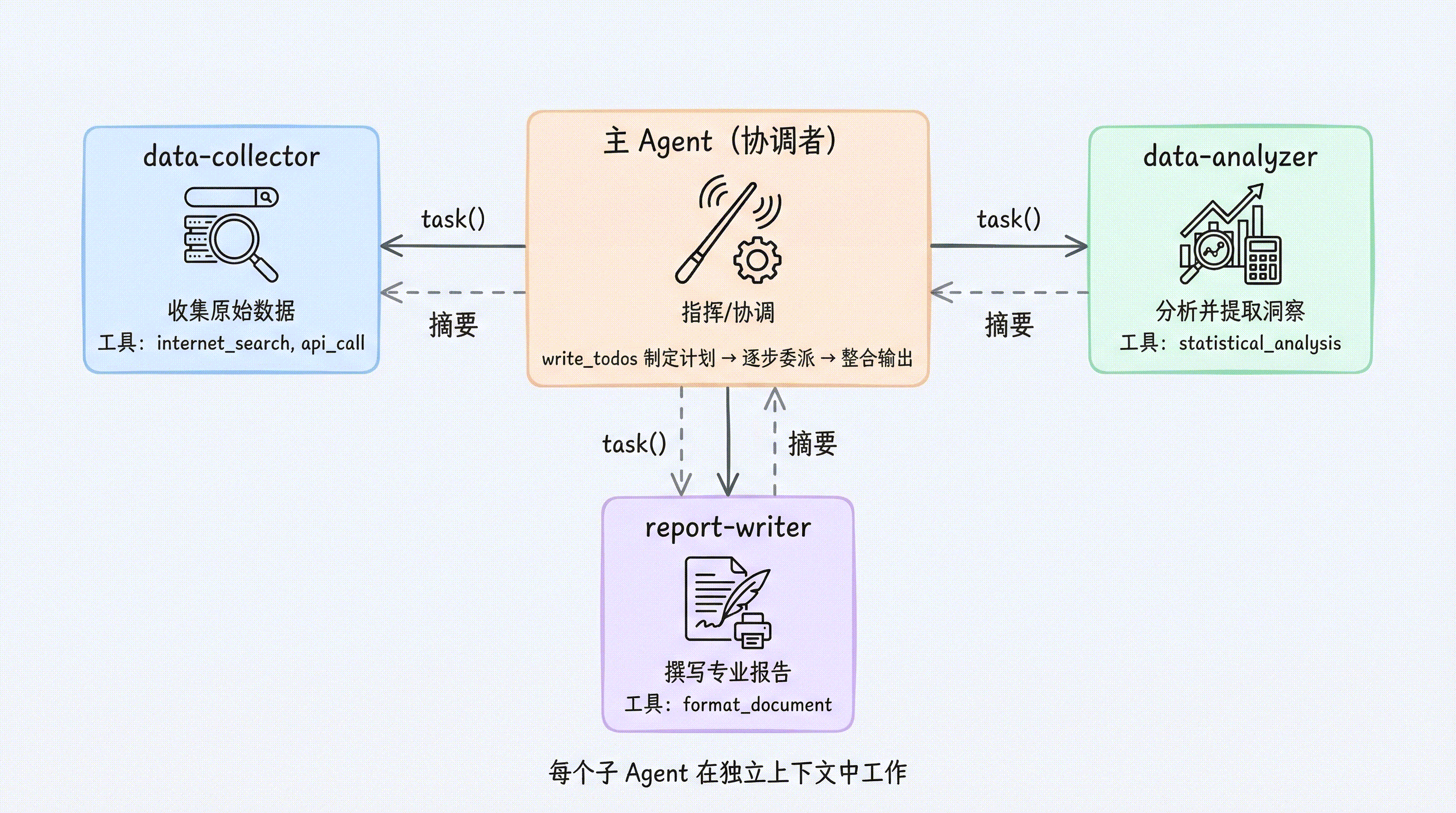
执行流程:
- 主 Agent 制定计划(
write_todos) task(name="data-collector", task="搜索 AI Agent 领域的最新趋势")→ 返回数据摘要task(name="data-analyzer", task="分析以下数据...")→ 返回关键发现task(name="report-writer", task="根据以下发现撰写报告...")→ 返回报告- 主 Agent 整合输出
每一步的子 Agent 都在独立上下文中工作,主 Agent 只看到精炼的返回结果。
结构化输出:让子 Agent 返回 JSON
默认情况下,主 Agent 收到的是子 Agent 最后一条消息的自由文本。通过 response_format 字段,可以让子 Agent 返回符合 Pydantic schema 的 JSON,方便主 Agent 程序化处理:
from pydantic import BaseModel, Field
from deepagents import create_deep_agent
class ResearchFindings(BaseModel):
summary: str = Field(description="研究摘要")
confidence: float = Field(description="置信度 0-1")
sources: list[str] = Field(description="信息来源 URL 列表")
research_subagent = {
"name": "researcher",
"description": "研究特定主题并返回结构化发现",
"system_prompt": "深入研究给定主题,返回你的发现。",
"tools": [internet_search],
"response_format": ResearchFindings, # 需要 deepagents>=0.5.3
}
agent = create_deep_agent(model=model, subagents=[research_subagent])
# 主 Agent 的 ToolMessage 将收到:
# '{"summary": "...", "confidence": 0.87, "sources": ["https://..."]}'不设置 response_format 时主 Agent 收到自由文本;设置后主 Agent 始终收到符合 schema 的有效 JSON。
子 Agent 最佳实践
1. 描述要具体
主 Agent 靠 description 决定何时以及委派给谁。描述越具体,路由越准确:
# ✅ 好的描述
"description": "执行深度网络研究,需要多次搜索、信息交叉验证和综合分析时使用"
# ❌ 差的描述
"description": "做研究"2. System Prompt 要详细
特别是要包含输出格式要求和字数限制——这直接影响返回给主 Agent 的内容质量:
"system_prompt": """你是一位研究员。
工具使用指导:
- 用 internet_search 搜索信息,每次查询不同的关键词
- 搜索 3-5 次以获取全面的信息
输出格式:
- 摘要(2-3 段)
- 关键发现(要点列表)
- 信息来源(附 URL)
重要:返回结果控制在 500 字以内。"""3. 工具集要精简
最小权限原则——只给子 Agent 它需要的工具:
# ✅ 精简:只给研究相关的工具
research_agent = {"tools": [internet_search]}
# ❌ 冗余:给了不需要的工具
research_agent = {"tools": [internet_search, send_email, delete_file, execute_code]}4. 不同子 Agent 用不同模型
根据任务特点选择合适的模型:
subagents = [
{
"name": "quick-lookup",
"description": "快速查询简单事实",
"tools": [internet_search],
"model": ChatOpenAI( # 轻量快速模型
model="THUDM/glm-4-9b-chat",
api_key=os.environ["SILICONFLOW_API_KEY"],
base_url="https://api.siliconflow.cn/v1",
),
"system_prompt": "快速查找并返回简洁答案。",
},
{
"name": "deep-analyst",
"description": "执行需要深入推理的复杂分析任务",
"tools": [internet_search, statistical_analysis],
"model": ChatOpenAI( # 强推理模型
model="Pro/zai-org/GLM-5",
api_key=os.environ["SILICONFLOW_API_KEY"],
base_url="https://api.siliconflow.cn/v1",
),
"system_prompt": "深入分析并提供详细的推理过程。",
},
]5. 返回结果要精简
在 system_prompt 中明确要求子 Agent 只返回核心内容:
"system_prompt": """分析数据并返回:
1. 关键洞察(3-5 条)
2. 置信度评分
3. 建议下一步行动
不要包含:原始数据、中间计算过程、详细的工具输出。
控制在 300 字以内。"""这一点至关重要——如果子 Agent 把大量原始数据返回给主 Agent,就失去了上下文隔离的意义。
常见问题排查
子 Agent 没被调用——主 Agent 自己做了所有工作
原因:主 Agent 无法从 description 判断何时应该委派。
解法:
- 让 description 更具体、更行为导向:
# ✅ 具体
"description": "执行深度网络研究,需要多次搜索、交叉验证和综合分析时使用"
# ❌ 模糊
"description": "帮助完成任务"- 在主 Agent 的
system_prompt中明确指示委派:
agent = create_deep_agent(
...,
system_prompt="""...你的指令...
重要:面对复杂任务时,使用 task() 工具委派给对应的子 Agent,保持自身上下文干净。""",
)上下文依然膨胀
原因:子 Agent 返回了大量原始数据。
解法:
- 在子 Agent 的
system_prompt中强制要求简洁返回:
system_prompt="""...
重要:只返回核心摘要,不要包含原始搜索结果、中间计算或详细工具输出。回答控制在 500 字以内。"""- 让子 Agent 把大量数据写入文件,只返回分析摘要:
system_prompt="""收集到大量原始数据时:
1. 用 write_file 将原始数据保存到 /data/raw.txt
2. 处理并分析数据
3. 只把分析摘要返回给主 Agent"""调用了错误的子 Agent
原因:多个子 Agent 的 description 过于相似,主 Agent 无法区分。
解法:在 description 中明确区分各子 Agent 的使用场景:
subagents = [
{
"name": "quick-researcher",
"description": "用于简单、快速的查询,只需 1-2 次搜索。适合查找基本事实或定义。",
},
{
"name": "deep-researcher",
"description": "用于复杂、深入的研究,需要多次搜索、综合和分析。适合生成全面报告。",
},
]小结
本章我们学习了 Deep Agents 的子 Agent 机制:
- 核心动机:Context Quarantine(上下文隔离)——子 Agent 在独立上下文中工作,只返回精炼结果给主 Agent
- 字典方式定义:必填字段
name+description+system_prompt(3 个);tools默认继承主 Agent,显式指定后完全替换;另有model/middleware/interrupt_on/skills/response_format/permissions可选字段 - General-purpose 子 Agent:默认可用,继承主 Agent 的全部能力(包括 skills);可通过
GeneralPurposeSubagentProfile(enabled=False)禁用 - CompiledSubAgent:用预构建的 LangGraph 图作为子 Agent,适合复杂多步骤工作流
- 结构化输出:通过
response_format让子 Agent 返回 JSON,方便主 Agent 程序化处理(需 deepagents>=0.5.3) - 最佳实践:描述要具体、提示词要详细、工具集要精简、模型按需选择、返回结果要精练
下一章(第 8 讲),我们将学习 Async Subagent——异步委派与并行协同,让主 Agent 同时驱动多个子 Agent 并行工作。